今天早上,老黄再次穿戴皮衣,在中国台湾省带来了一场 GTC ( GPU 本事大会 )。
和之前不一样的是,此次老黄先上来感谢了一波合作伙伴。
比如什么王记府城肉粽啊、花娘小馆啊、肉霸王猪脚啊。。。
滚球中国官方网站入口?

你这是什么合作伙伴?
老黄干饭的合作伙伴吗?
径直大中午给屏幕前的给托尼看饿了。
天然了此次 GTC 也不是全是吃货,托尼听完毕所有演讲后,发现老黄本年给众人憋了两波大的。
>/ 微软和英伟达正在从新界说所有 PC 产业
此次,老黄莫得忘了我们这些臭打游戏的。
话未几说,径直掏出了 RTX Spark,也即是之前神话许久的 N1X 惩办器。
看成 NVIDIA 与微软、联发科 ( MediaTek ) 深度合作的结晶,RTX Spark 一伊始,即是想突破 40 年以来传统电脑的架构局限。
等会,哪儿局限了?是冯诺依曼架构不行了,如故制程工艺发展到极限了?
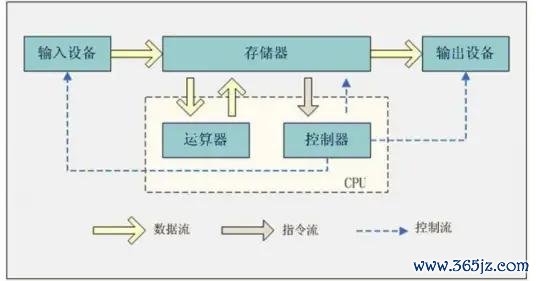
其实齐不是。要托尼说啊,PC 目下边临的真的问题是:
传统 PC 架构和土产货 AI 的需求产生了严重冲突。
浅易点来说,即是目下的电脑压根不合适跑土产货 AI。
显卡里的显存天然能跑 AI,然而显存的容量实在是太小了,即使是最旗舰的 5090 显卡,也只可给到 32GB 的显存,你想跑的模子略微大少量,那就径直打出 GG。
而电脑里常用的内存天然容量够大,然而读写的速率又太慢了,让它来跑大模子,确乎有些难为东谈主。
是以在传统 PC 上跑 AI,一直是个大问题。
直到苹果 M 系列惩办器的出现。M1 芯片把 CPU、GPU、NPU 和高带宽内存沿途封装在一颗 SoC 里,搞了套和谐内存架构出来,才让众人发现 AI 正本不错这样搞。

不分什么内存,显存,CPU 和 GPU 共用合并个内存池。莫得所谓显存的枷锁,能给 AI 用的内存可就多太多了。
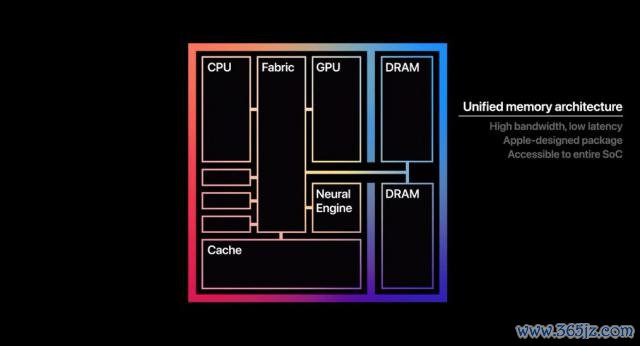
是以这两年我们能看到,果果的 Mac Studio 靠着最高 8 通谈、512G 内存,跑 AI 实在太香了;AMD 这边也推出了 AI Max+ 395,天然性能稍逊,但经受了近似的架构,在 128G 内存的加合手下,分一部分给显卡也足以跑动中等参数目的模子。

这些能跑 AI 没错,但他们对 AI 的赞助,永恒差了点意念念。要说 AI 生态最佳的,不是苹果,也不是 AMD,而是深耕 CUDA 生态这样多年的英伟达。
无意是不肯眼看着土产货 AI 这块市集拱手让东谈主,又无意是看到了智能体 ( Agent ) 期间大爆发,总之老黄是真坐不住了。

凭什么你苹果和 AMD 能作念和谐内存架构,我老黄就不行作念呢?
于是,RTX Spark 来了。这玩意的 CPU 部分是英伟达与联发科合作定制的 Grace CPU,由 20 个 Arm 中枢构成。把柄目下爆料的跑分,或者是和几年前苹果的 M3 Max 差未几的水平。
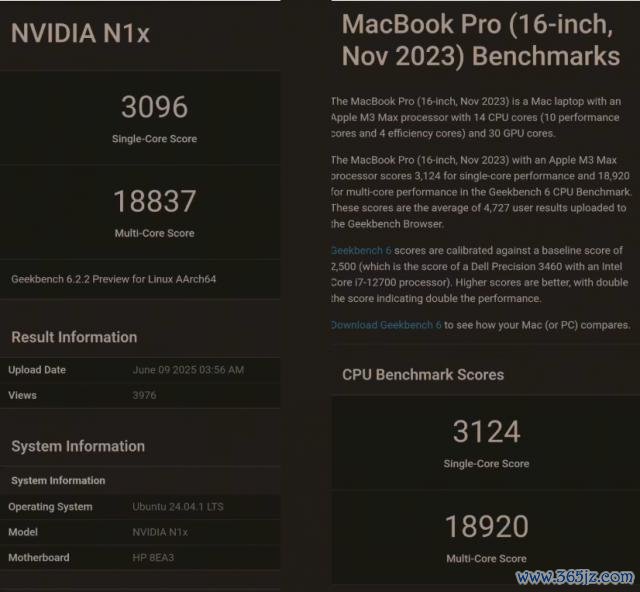
而 GPU 方面则是塞进去了 48 个流惩办器,估计 6144 个 CUDA 中枢,性能极端于桌面端的 5070 显卡。这个规模可少量齐不小。如果论 AI 更和蔼的算力来看,在 NVFP4 精度下,可达 1P,也即是 1000 TOPS 的水平。
看成 AI 期间的惩办器,RTX Spark 也吃上了和谐内存,最高 128G 的容量,不错跑不少模子了。
仅仅这个和谐内存的读取速率唯一 273 GB/s 的速率,和 AMD 的 AI Max+ 395 在一个水平,比果果低了一些。不外 CPU 和 GPU 之间倒是径直用上了工作器端的 NVLink,最大 600 GB/s 的带宽,完爆了传统 PC 上的 PCIe 互联。
是以这玩意骨子跑起来是个什么水平,还得等精采平直了再碰侥幸才知谈。
天然,英伟达最大的杀手锏,如故 CUDA 生态能让各式 AI 应用快速跑起来。
在现场老黄就演示了这样一个场景:通过 Agent 串联 ComfyUI、Blender 等器具,在一台个东谈主电脑上就能完成房间绘画、建模、渲染、AI 生成预览图的全套经过。
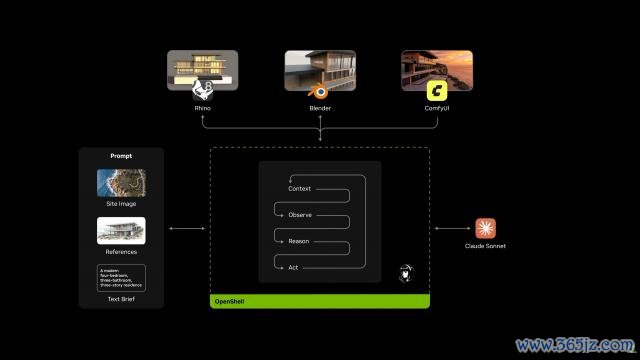

哎,我那时装修要有这玩意该多好。
咳咳,扯远了哈,在 AI 以外,英伟达也曾的老本行——游戏,在 RTX Spark 上也没忘掉。以 RTX Spark 的规模,跑个 2K 游戏没什么问题。
况兼在之前的 Windows on Arm 上面疼的反舞弊问题,老黄和微软也作念了奋勉,买通了 Easy Anti-Cheat 和 BattlEye 等主流 PC 网游反舞弊底层组件的 ARM 原生兼容。

老黄还赶快端出来两台条记本,一台跑着最新的《007》,另一边也跑着最新的《地平线 6》,托尼还挺意思意思实机的兼容性到底怎么样。
淌若有契机的话天然是要给差友们测试一波的。

>/ 造一块不给东谈主用的 CPU:
天然,Kaiyun中国大陆开云体育官网入口除了护理我们这些正常阔绰者以外。
真的能给英伟达赚大钱的工作器行业,老黄也没落下。
此次,它们一经不自恃于把 CPU 卖给东谈主类了。

在英伟达的眼里,目下的 CPU,一经跟不上 GPU 的念念必得了。
在现场老黄打了个比喻,说如果 GPU 是一个乐团的话,那么 CPU 即是这个乐团的领导家。

乐团想要演奏出合适的音乐,那领导的手速必须得跟上。

而目下,跟着 Claude Code、龙虾这样的 Agent 器具越来越火, CPU 干活的速率,一经自恃不了 GPU 了。
举个例子,我们让 Agent 应付干点活,让它帮我去总结一下英伟达最新一季的财报。
这时辰,CPU 就要负责去网上找点远程,先证实最新的财报是哪一季的,然后再去网上搜索,找到方针后,再跑个下载剧本把财报给下过来。
把这些活齐给干完毕之后,才会精采初始财报分析。
归来所有经过,你会发现 Agent 它没目标一次性把活给干完。
齐是先让 GPU 干点活,然后让 CPU 致力再干点活,接着再让 GPU 来干活的连环瓜代类型。
如果 CPU 性能不够高的话,那么 GPU 径直初始在原地空等,那不是纯纯浪费么。
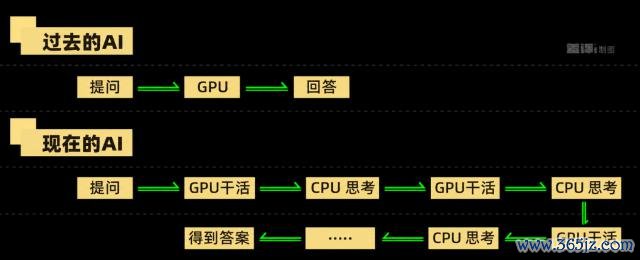
老黄径直摊牌了,说目下的 CPU 一经成了 GPU 应用率的瓶颈。

是以此次,他们特地造了一款给 Agent 器具用的 CPU —— NVIDIA Vera。

这玩意不错说从新到尾齐是盯着这一件事延伸来优化的。
昔时,绝大无数的工作器 CPU,其实齐是由好几个小芯片给拼起来的,这样作念的克己是你作念芯良晌的良率更高,资本更低。
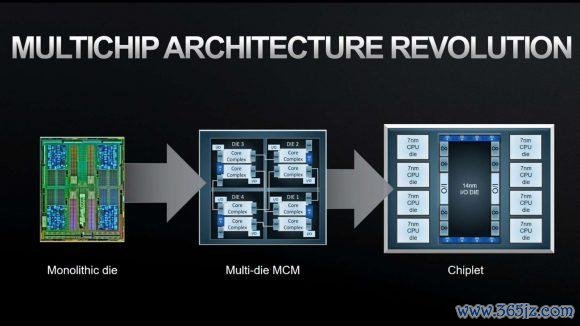
坏处即是中枢和中枢之间的通信速率就没那么快了,中枢和中枢之间想发条音问,得去外头绕一圈路。
而 Vera 就没这样打扰了,为了让它干活干的更快,老黄径直把 88 个计较中枢给作念在了一块芯片上。
这就让这些中枢之间的通信速率径直栽培了 50%,双车谈变三车谈了属于是。

况兼老黄还给东谈主保留了一条稀奇的高速公路,Vera CPU 不错通过 NVlink 径直和 GPU,或者是另一枚 CPU 来相易数据。
这样几板斧下来之后,Vera 干活的速率一经被老黄调教的有些夸张了。
老黄拿 Starburst 的 SQL 分析测试举了个例子,在雷同的分析数据的基准测试里,Vera 的运行速率是 X86 CPU 的 3 倍。

在纽约交所的及时流测试里,Vera CPU 更是硬生生把计较延伸给压到了正本的六分之一。
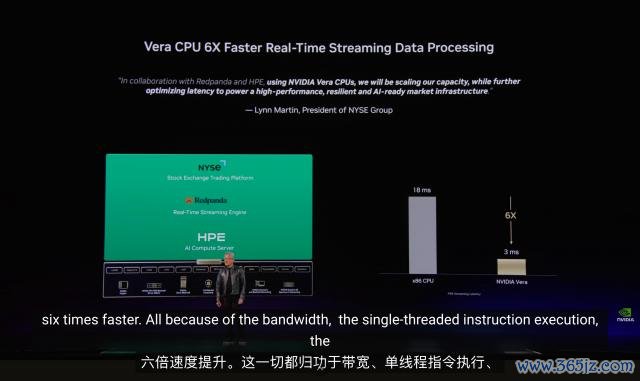
淌若有这机房来让我炒股,那可能巴菲特来了齐得叫托尼一句股神了。
>/ 被 AI 再次塞满的英伟达
天然,除了这两颗 CPU 以外,老黄此次的 GTC 还共享了不少好玩东西。
其中有教你怎么建数据中心的赛博攻略 DSX。
让你在真的破土动工之前,用模拟软件先把工场的电力、冷却、汇集环境给模拟测试一遍。

还有一整套给 Agent 用的大礼包,有面向企业的 Agent 器具套件,还有让 AI 幽静安全的 OpenShell 框架。。。
终末还拿出了一个给机器东谈主和自动驾驶准备的寰宇模子:Cosmos 3 .
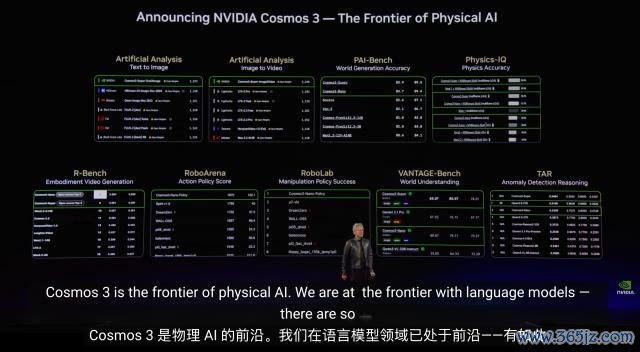
一言以蔽之,此次的老黄,再次给我们缠绵了一个被 AI 给塞满了的寰宇。
这些东西齐很酷,不外对托尼来说,可能最和蔼的,如故前边提到的 Spark。
在昔时四十年里,PC 市集永恒被 Intel 和 AMD 构成的 " 双雄定约 " 紧紧把合手。高通天然领先进犯 Windows ARM 生态,但不管是 GPU 硬件实力,如故 Windows 上的 DirectX 生态,齐总透着一股水土叛逆的滋味。
况兼全新平台的起步,连接伴跟着软件缔造商与 OEM 厂商关于平台 " 浅尝辄止 " 的担忧。这亦然 Windows 条记本在目下适度,仍然以传统的 X86 为主的原因之一。
好在英伟达亦然知谈新平台的蔓延难度的。一方面,老黄晓喻了畴昔直到 2030 年的本事道路图,目下是 Blackwell Spark,畴昔则是 Rubin Spark 和 Rosa Feynman Spark。
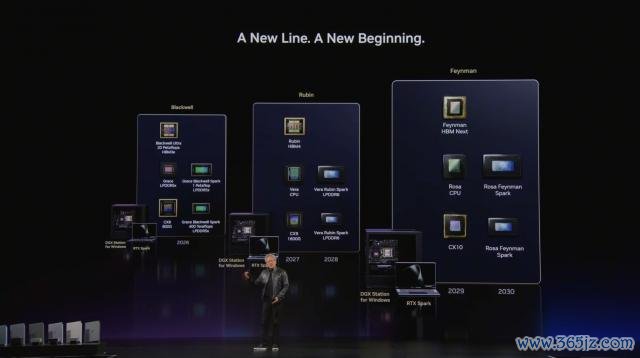
换句话说,RTX Spark 这条路,老黄是作念好了打合手久战的脸色准备。。。
再说了,有着 RTX 和 CUDA 这两块金字牌号的号令力,就算要搞软件和游戏的底层适配,那速率和积极性,也整个不是也曾的高通 × 微软定约能比的。
目下球一经传出去了,老黄这边不错说是尽了东谈主事,下一步,压力全给到了微软这边。
无论如何,RTX Spark 能否蔓延出去,一方面取决于产物订价,另一方面取决于 Windows on ARM 本人能否支棱起来。
撰文:洛洛 & 早起
裁剪:江江 & 面线
好意思编:素描
图片、远程起原:英伟达官网


